
We all know that great swathes of the web are simply garbage – absurd listicles, the detritus of content farms living a zombie existence, abandoned social networks, virtually everything on Twitter. It all has some fascinating value in the future just as scientists and historians learn things from the actual physical garbage of the past. But one of the amazing things about the Internet is that in addition to all the garbage and trash the web contains almost limitless different niches of treasures. One of the ones I’m continually bowled over by is the digitization of archival material in the world’s great archives and research libraries. Take the British Museum or the British Library or the Library of Congress or countless other repositories around the world. Sure, they all have websites, which tell you some information about their holdings. But one of the great projects (multitudes of programs) over the last thirty years is the digitization and digital publication of a great swathe of the historical riches of global civilization.
I saw some of this up close when I was training to be an historian in the 1990s. When I began in 1992, by and large, if you wanted to review historical documents in a particular area you needed to go to whatever library or archive had them. I was lucky because I was studying early New England at a university in New England. So I was seldom more than a car ride away from things I needed to look at.
New England has been a region of deep self-concern and power for centuries. So quite a lot has been preserved. Still, it was remarkable how haphazard some of it could be. I remember very clearly, probably in 1994 or 1995 finding some land records I was looking for from the 1640s wedged under a shelf in the basement of what I think the Warwick, Rhode Island town hall. WTF? Many of the most important government records from 17th century New England were published in book form in the very early 19th century. So you can look at copies of those in most of the region’s major libraries.
In any case, I was doing research full time in the mid-90s. Then I sort of put all that on the back burner and started trying to become a journalist. So I had my dissertation in semi-limbo for a few years – most of it written and most, but not all, of the research done. By late 2002, with TPM up and running and other projects underway, I realized that the balance of time was starting to run against me. If I didn’t finish soon I never would. So I set aside time to finish my research and writing. In the event, most of the time I set aside I ended up not having because I was already chained to the news of the day. But I did get it done. Even by 2002 and 2003, though, things had changed pretty significantly. One thing is I actually had a little money so there were some books I could just order rather than going to a library to read them. More importantly, a lot of material that only existed for review in person had been digitized and put online.
Now of course the pace of digitization has progressed massively. But there’s so much more than items that would be of interest only to researchers working in particular areas. Do you want to see what the Gutenberg Bible actually looks like? You can see fully digitized versions at the Morgan Library & Museum or at the British Library or a number of other archives.
And these aren’t just screen grabs for you to get a taste of what they look like. These projects are intended for scholarly research, both the content of the text and sufficiently high quality imagery that physical artifacts themselves can be studied.
Or here’s another example, in a way obscure but also one of the most important manuscripts in global history. It’s called the Codex Siniaticus. It’s one of two more or less complete manuscripts of the Christian bible that dates back to the middle of the 4th century – like maybe around 350 AD. (The other is the Codex Vaticanus, which is roughly the same age but likely two or three decades older.) At one level it’s remarkable that something written on parchment within a couple decades of the death of the Emperor Constantine still exists. But if you’re interested in the history of the text of the Christian bible and getting as close to the original writing as possible – either for historical or religious reasons – this is a critical text. When scholars began scrutinizing these two texts closely in the 19th century they realized that they different in significant ways from the so-called ‘received text’ that had been handed down through the centuries.
The modern history of Siniaticus is almost as interesting as its ancient pedigree. The Codex was discovered at the Monastery of St Catherine in the Sinai desert in the middle of the 19th century by a German biblical scholar named Constantin Tischendorf. He later went to work for the Tsar Alexander II of Russia and persuaded the monks at St Catherine’s to give the text to the Tsar. It lived in Russia for the next seven decades. Then in the early 1930s, a cash-strapped Soviet Union sold the Codex to the British Museum for 100,000 pounds. That’s where most of it still is. But there are a few scraps of it still in Russia, in Leipzig and even a few at St Catherine’s. So there’s a Codex Siniaticus Project where each of four repositories have reunited all the known portions digitally. You can see the entire manuscript here.
Here, for instance, is most of the 2nd chapter of Paul’s Letter to the Romans.

(As you can see, punctuation and even word separation are developments of the Middle Ages and Renaissance. Ancient texts don’t have either.)
Now, admittedly, you probably can’t read any of this since you can’t read Latin or Koine Greek (except a few of you). But there’s a wealth of artifacts from the distant past that are far more accessible. Here’s one example. The John Carter Brown Library at Brown University is one of the most important archives in the world for the study of the Americas before 1825 – in other words, the colonial era, North and South. There are many paths into the digitized portion of their collections. But here for example is their collection of historical maps broken down by date, type, region and mapmaker – maps dating from 1482 to 1932. You can see any of them with just a click. Here are all the maps of the globe and there are hundreds of specific regions.
Let me show you a few examples.
Here for example is a world map from 1508. (With each example, simply click the image to see a larger version.)
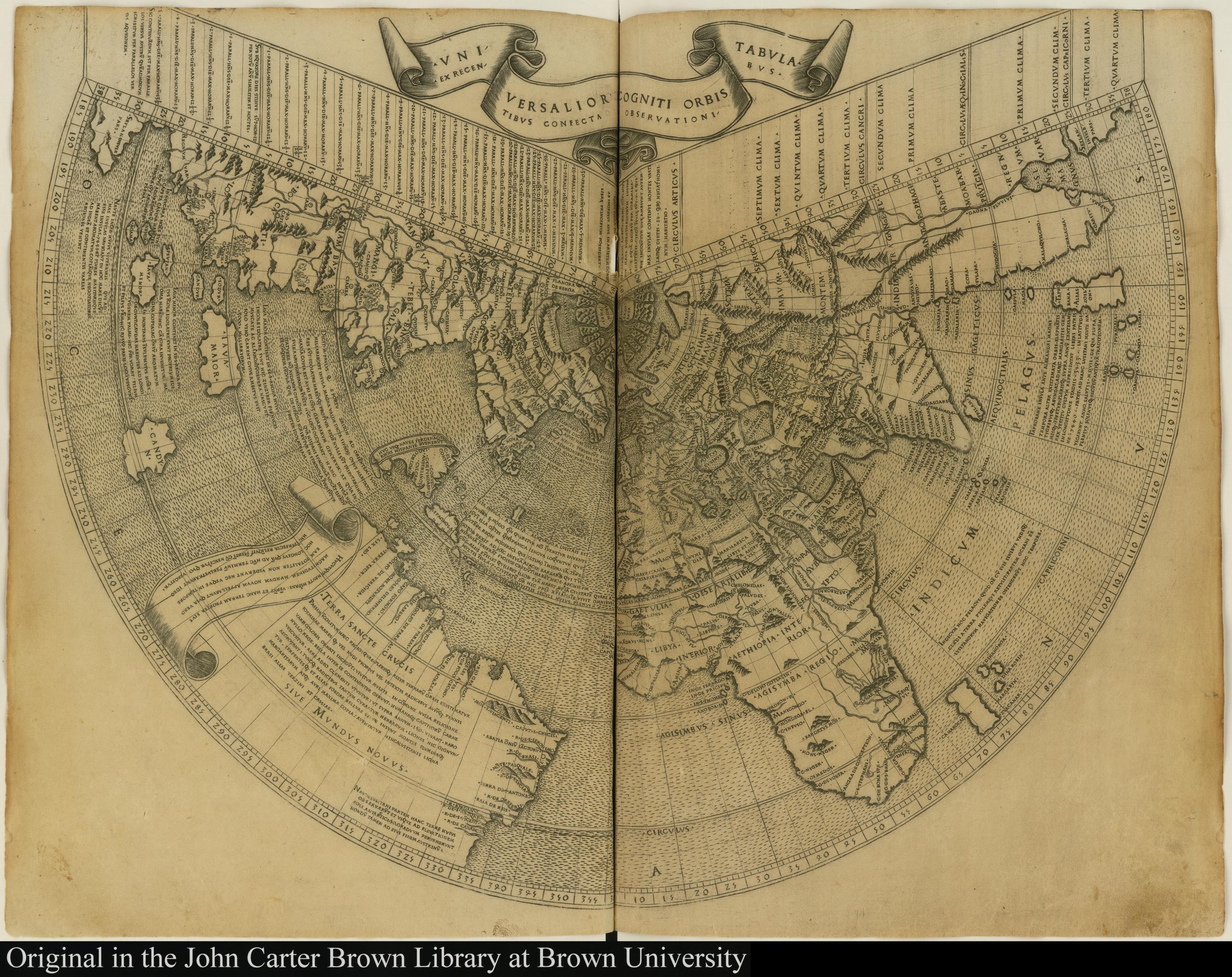
Here’s another from 1513.
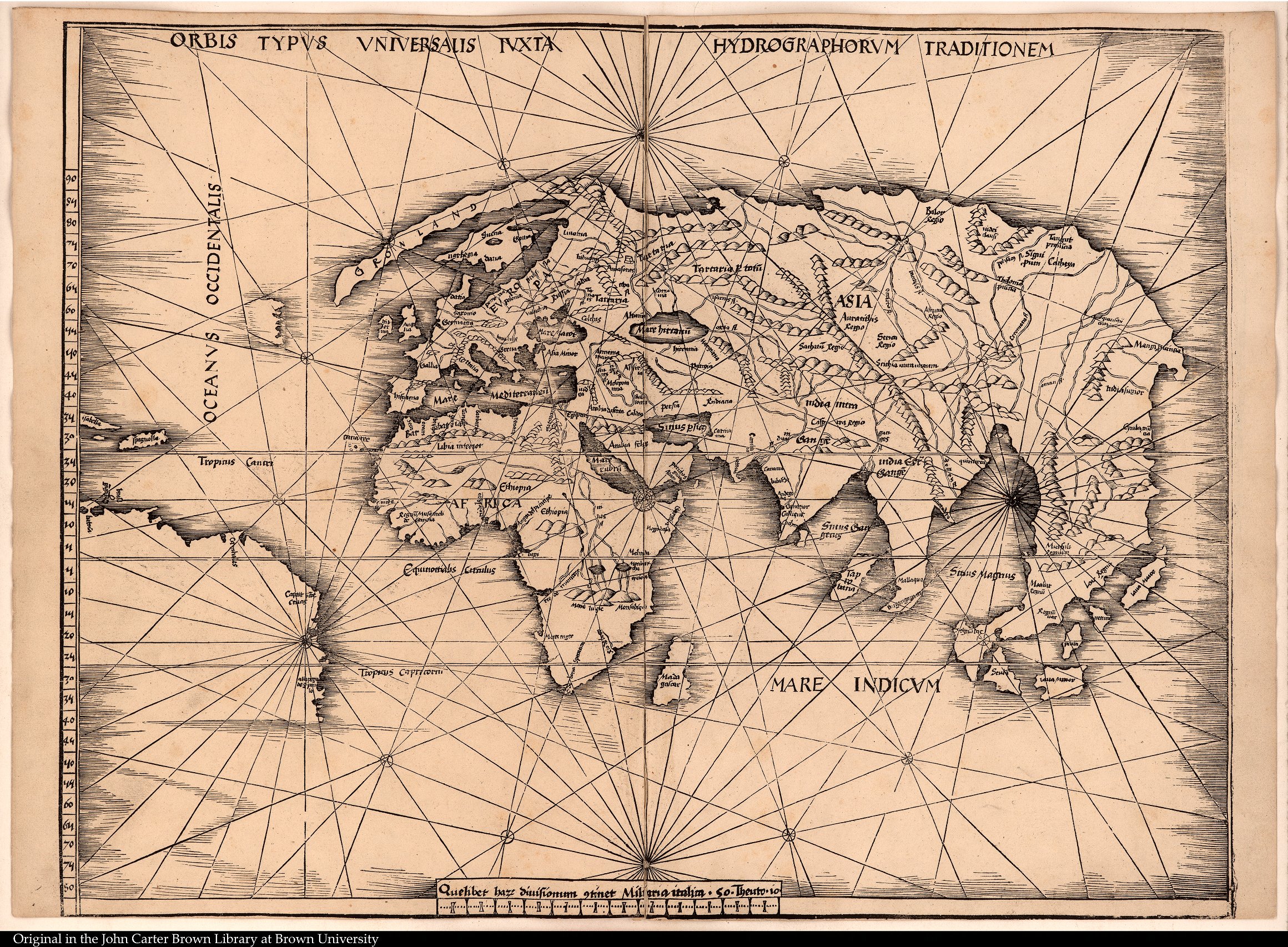
Here’s one published in 1608.

And here is one from 1702.

For a different collection, here’s the digitized manuscript collection at the British Library.
Or let’s move to something entirely different. In 1995 The Library of Congress purchased The William P. Gottlieb Collection. Gottlieb was a Jazz journalist and photographer. The photograph part of the collection contains photographs of primarily (but not exclusively) legendary Jazz artists from the 1940s – all online and searchable.
Here’s Dizzy Gillespie, 1947.

Charlie Parker, Tommy Potter, and Max Roach, 1947.

Doris Day, 1946.

Howard McGhee and Miles Davis, 1947.

The stuff online at the Library of Congress is almost limitless. They have digitized about half of the Papers of Abraham Lincoln, the Papers of Frederick Douglass, a collection of 2,000 maps of North America and the Caribbean from the years just before and after the American Revolution, Ansel Adams photographs from the Japanese-American internment camp at Manzanar, the Civil Rights History Project. You can browse more here.
There is a more complex process underneath all these digital riches which is just how to preserve digitized collections to stand the test of time. With books, by and large, you just take care of them. Easier said than done and world class libraries now have a complex set of practices to preserve physical artifacts from acid-free containers to climate control and the like. But there’s an entirely different set of issues with digitization. It would certainly suck if you’d digitized your whole collection in 1989 and just had a big collection of 5 1/4 inch floppy disks produced on OS/2, the failed IBM-backed PC operating system that officially died in 2006.
That’s just an example for illustration. But you can see the challenge. Over the last 30 or 40 years we’ve had Betamax, VHS, vinyl albums, CDs, DVDs, BluRay, various downloadable video and audio formats. These are all a positive terror if you’re trying to organize and preserve artifacts of the past that people will have some hope of using in a century or five centuries. What formats do you use? How do you store them – not simply to make them available today but to ensure they aren’t lost in some digital transition or societal disruption in the future? A DropBox account won’t get it done.
Happily, for those of us who are merely consumers of these riches in the present, it’s someone else’s problem. But it is a big, fascinating problem for librarians and digital archivists around the world.
If you’ve found digital archives that you think are worth sharing with other members of the TPM community, drop me a line with some good links.



